业务平台的冷数据查询功能支持了clickhouse,在调研和上线过程中,均遇到了一些查询会触发全表扫描导致查询超时的情况,因此这里想深入排查下原因,探索一些可能的优化措施。
测试准备
建表如下:
CREATE TABLE IF NOT EXISTS gamelog (
hostname String,
m_group String,
m_service String,
base_category String,
base_category_id String,
batch_ts Int32,
category_id String,
epoch_microsecond Int32,
path String,
msg String,
imestamp DateTime
) Engine = MergeTree
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (timestamp)
SETTINGS index_granularity = 8192
创建索引如下:
ALTER TABLE gamelog ADD INDEX IF NOT EXISTS idx_msg msg TYPE tokenbf_v1(30720, 2, 0) GRANULARITY 1
这里省略数据写入的过程,最终写入数据 626w 左右。
查询
1. like 查询
首先使用like查询msg中匹配 %蒸汽Citypop%的日志行:
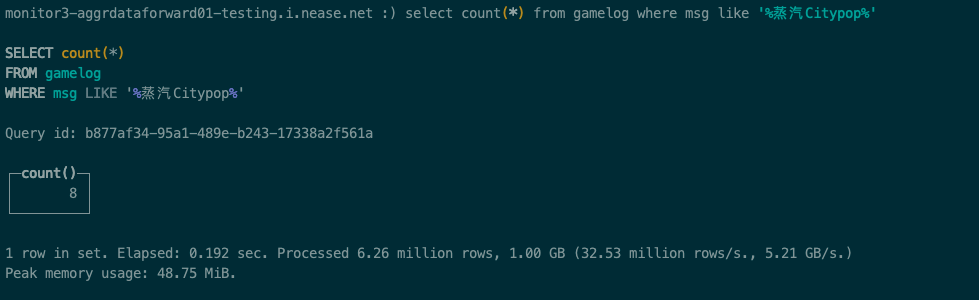
从上面的查询结果来看,整个查询耗时192毫秒,扫描数据626万条,这就是全表扫描了。说明虽然创建了一个跳数索引,但是对查询没有任何的优化效果。
我们可以通过执行计划来印证这一点,在SQL语句前加上EXPLAIN,即可查看执行计划,再加上indexes = 1, 就可以查看走到的索引的情况:
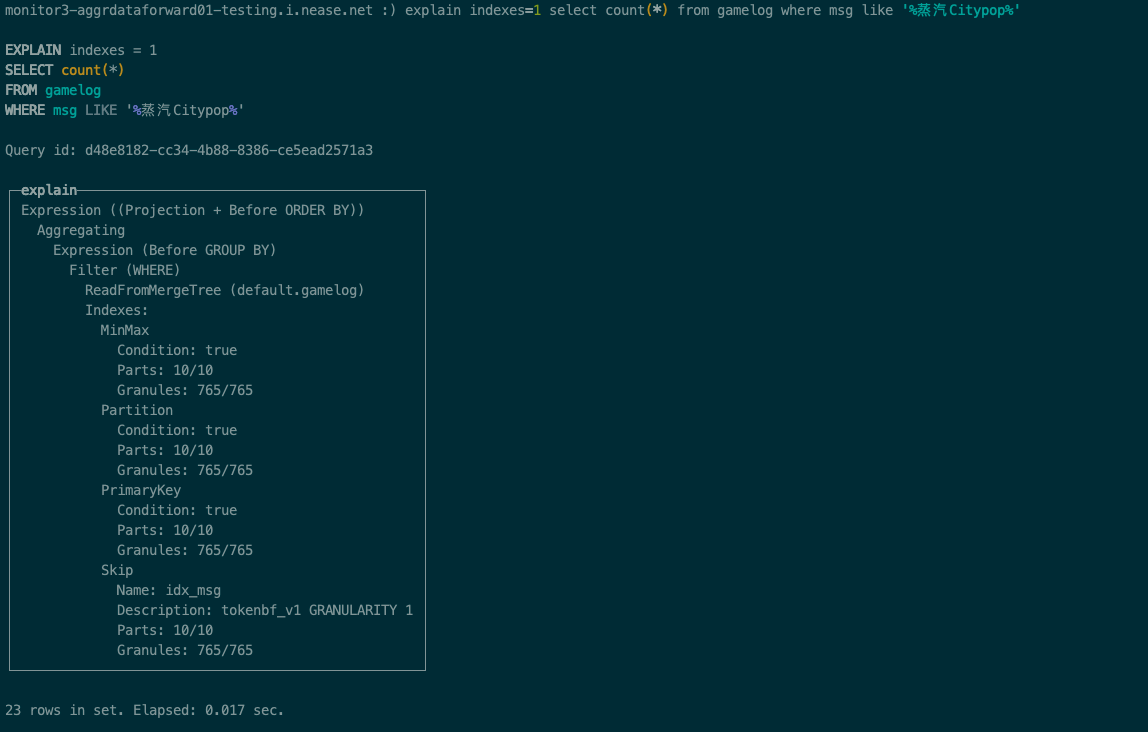
执行计划如何看?
Filter一开始,是10个part,一共765个索引。每个索引粒度都是8192, 所以一共是 8192 * 765(=626w) 条数据,这个和我们的数据总量是对应得上的;
首先有一个MinMax,这个一般是根据建表时的ORDER BY的字段进行筛选,因为我们没有带任何timestamp的筛选范围,所以MinMax筛选完还是765个数据块;
然后是Partition,也就是分区。正常来说,如果按天分区,查最近一小时数据,它肯定不会走到昨天的分区里去查找数据,可以通过这种手段直接排除掉一些不可能走到的分区。因为我们的数据都在同一个分区,所以过滤不掉,还是765个数据块;
接下来是PrimaryKey, 我们没有显式地指定主键索引,所以默认使用ORDER BY的字段作为主键索引,也是没有过滤掉数据,还是765;
注意最后面的Skip,这个指的就是跳数索引,可以看到idx_msg正是我们创建的索引,说明这个查询,这个索引确实走到了,但是过滤完,还是765个数据块,说明虽然走到了这个索引,但是一条数据都没有过滤掉。
2. hasToken 查询
接下来使用hasToken查询msg中匹配 蒸汽Citypop的日志行:
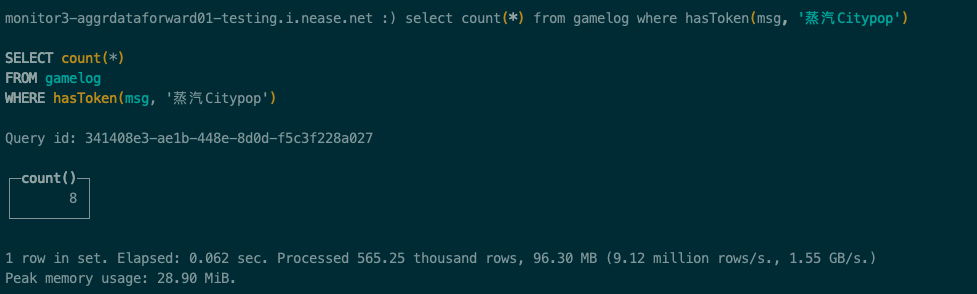
从上面的查询结果来看,整个查询耗时62毫秒,扫描数据56w条,比like查询速度要快,扫描数据也少很多。说明跳数索引对查询起到了优化效果。
我们同样来看执行计划:
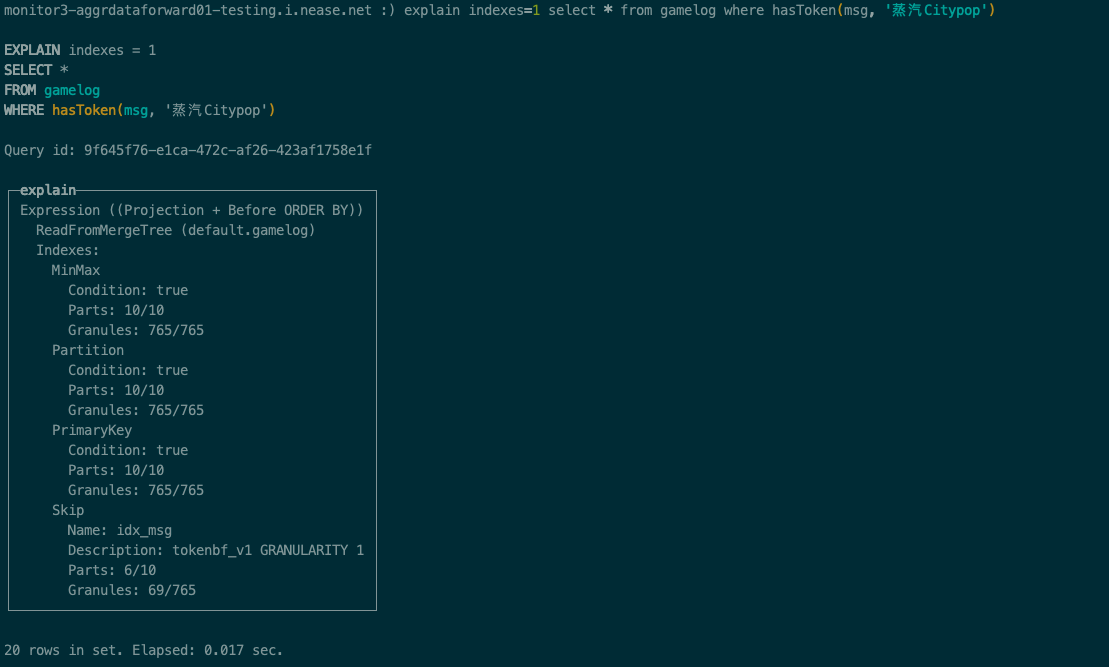
前面跟like查询是一致所以这里忽略掉,直接看 Skip 这部分,可以看到这里parts过滤后只剩下了6块,数据块过滤后只需要扫描69块,索引优化明显,因此查询速度比 like 查询快是符合预期的。
3. tokenbf_v1 索引
通过上面like和hasToken的查询对比,不禁让人怀疑前面使用的tokenbf_v1 索引是不是无法在like查询上生效?
在官方文档中可以找到答案:tokenbf_v1索引是支持like操作的

那么这里like操作为何无法使用索引进行查询优化?
这里我们稍微改下查询语法,用like查询msg匹配 % 蒸汽Citypop %,注意查询的短语前后分别填充了空格,直接看执行计划:
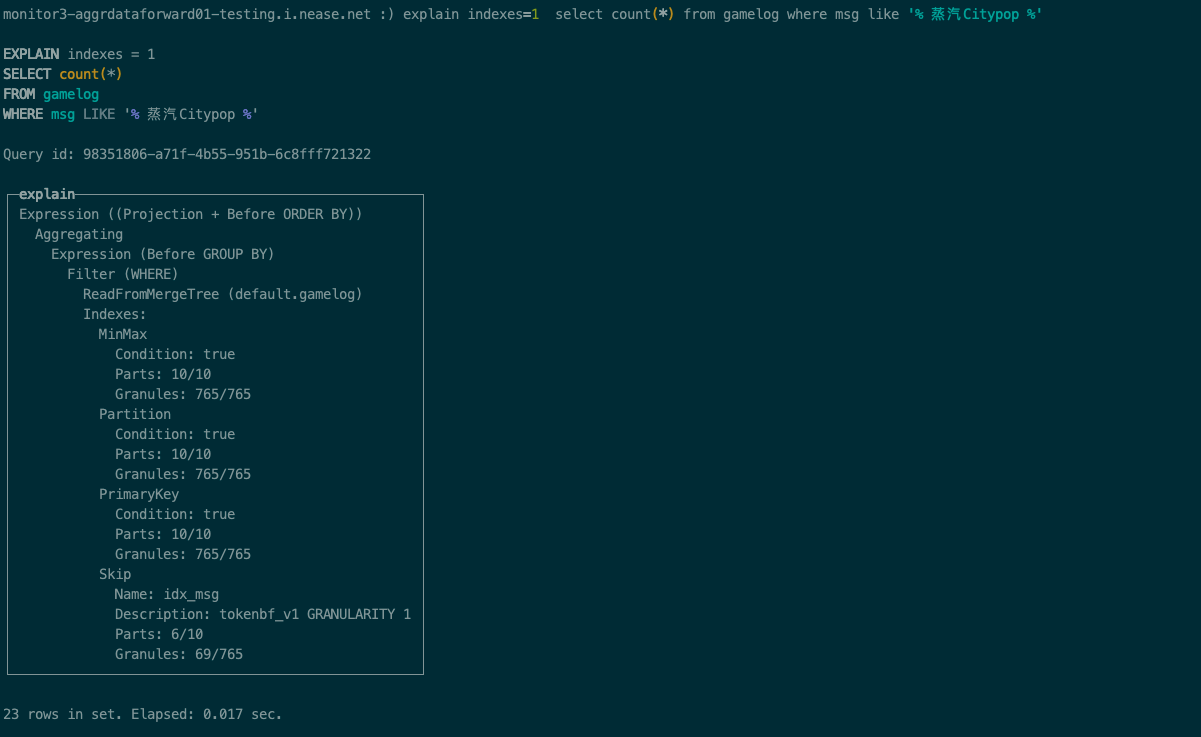
在 Skip 这部分,可以看到这里parts数据块过滤后的数量跟上面 hasToken查询一样,因此两者查询速度是一样的,也就是此处的like操作能使用到索引进行优化。
那么问题又来了,%蒸汽Citypop% 与 % 蒸汽Citypop % 这两个查询,后者只是比前者多了两个空格,为何就能命中到索引?这里要从 tokenbf_v1 索引的分词和查询原理说起。
tokenbf_v1 即 Token Bloom Filter,是 clickhouse Skipping Indexes的一种。tokenbf_v1 索引会将 granule 内的数据进行分词,然后将这些分词通过hash函数计算,最后构建出 bloom filter索引;查询时,同样将查询短语进行分词,然后将分词后的token通过granule的bloom filter索引进行匹配,如果未匹配成功,则过滤掉该granule,对于匹配成功的granule,还需要进行逐行匹配,将符合条件的数据提取出来,最后合并结果并返回。
tokenbf_v1 使用的是分隔符分词法,即按非字母数字字符进行分隔。这里可以直接看clickhouse的源码(src/Interpreters/ITokenExtractor.cpp)中对于分词的处理逻辑:
bool SplitTokenExtractor::nextInString(const char * data, size_t length, size_t * __restrict pos, size_t * __restrict token_start, size_t * __restrict token_length) const
{
*token_start = *pos;
*token_length = 0;
while (*pos < length)
{
if (isASCII(data[*pos]) && !isAlphaNumericASCII(data[*pos]))
{
/// Finish current token if any
if (*token_length > 0)
return true;
*token_start = ++*pos;
}
else
{
/// Note that UTF-8 sequence is completely consisted of non-ASCII bytes.
++*pos;
++*token_length;
}
}
return *token_length > 0;
}
nextInString 方法对原始数据data进行token提取,当遇到非字母数字时且为ASCII字符时,则提取出token,否则继续遍历data中的字符。
当我们使用hasToken方法时,参数必须为字母或数字组成的字符串,因此查询时无须再进行分词操作,而使用 like 操作时,参数则可以是任意的字符组成,那么这其中肯定涉及到分词操作,我们直接看源码(src/Interpreters/ITokenExtractor.cpp)是怎么处理的:
bool SplitTokenExtractor::nextInStringLike(const char * data, size_t length, size_t * pos, String & token) const
{
token.clear();
bool bad_token = false; // % or _ before token
bool escaped = false;
while (*pos < length)
{
if (!escaped && (data[*pos] == '%' || data[*pos] == '_'))
{
token.clear();
bad_token = true;
++*pos;
}
else if (!escaped && data[*pos] == '\\')
{
escaped = true;
++*pos;
}
else if (isASCII(data[*pos]) && !isAlphaNumericASCII(data[*pos]))
{
if (!bad_token && !token.empty())
return true;
token.clear();
bad_token = false;
escaped = false;
++*pos;
}
else
{
const size_t sz = UTF8::seqLength(static_cast<UInt8>(data[*pos]));
for (size_t j = 0; j < sz; ++j)
{
token += data[*pos];
++*pos;
}
escaped = false;
}
}
return !bad_token && !token.empty();
}
与 nextInString 方法类似,nextInStringLike 也是通过循环读取原始数据data来做分词处理。
第一个if分支中,判断遇到 ‘%’ 或 ‘_’ 字符时,则认为当前提取到的token为 bad_token,将token清空并设置bad_token为true。这里是因为 ‘%’ 和 ‘_’ 是LIKE操作中的特殊字符:

第二个if分支中,判断遇到’\‘字符则将 escaped 设置为 true,即表示遇到了转义符号
第三个if分支中,当遇到非字母数字时且为ASCII字符时,则提取token返回,注意当这里bad_token为ture时,是不会返回token的;举个例子,当 like 查询为 %abc% 或者 _abc_ 时,这两个查询中的abc都不能提取成 token。当 like 查询为 %abd-abc-bsd% 或者 _abd-abc-bsd_时,这两个查询中的abc就能提取成 token
最后的else分支中,将字符追加到了token中,支持UTF8字符,即支持了中文等其他语言。
回顾一下上面的 like 查询:%蒸汽Citypop% 和 % 蒸汽Citypop %,经过上面的分析我们可以知道前者无法提取出token,而后者则可以提取出 蒸汽Citypop 这个token,然后通过这个token,就可以使用 tokenbf_v1 的跳数索引。
优化措施
经过上面的分析,我们能了解到 clickhouse 出现慢查询的原因都是因为无法命中到索引,那么优化的方向就是尽量让查询能命中到索引:
1. 结合 like 和 hasToken 查询
这里可以判断查询的短语,如果仅包含数字和字母字符,那么查询ck时可以替换成 hasToken 查询;若查询包含了非数字和字母字符,则使用 like 查询。
通过结合 like 和 hasToken 查询,让查询效率最大化。
不过需要注意的是,当 like 查询使用 %xx%匹配时,为全匹配模式,而 hasToken 查询则只会匹配 token。举个例子,like查询 %abc% 可以匹配 aabcdef,也可以匹配 a abc def,但 hasToken('abc')只能匹配a abc def
2. 使用 ngrambf_v1 索引
将 tokenbf_v1 索引替换成 ngrambf_v1,ngrambf_v1和tokenbf_v1比较像,不过它不是按照token进行分词,而是根据长度进行分词。
举个例子,假设将A short string按照n=4进行分词,得到的结果如下:
['A sh', ' sho', 'shor', 'hort', 'ort ', 'rt s', 't st', ' str', 'stri', 'trin', 'ring']
ngrambf_v1相比于tokenbf_v1,优点是支持特殊字符查询,只需要对查询短语进行长度分词,无需区分特殊字符。
但缺点是n的长度一旦确定好就不好修改了,如果查询的关键词长度小于n,那么该索引也不会生效。因此ngrambf_v1非常看具体的查询场景,如果提前知道查询的短语范围,针对性的设置n的长度,是有非常大的优化效果的。
3. 使用 inverted 全文索引
inverted索引即倒排索引,它的原理和ES的倒排索引类似,分词器目前支持 tokenbf_v1 和 ngrambf_v1:
- inverted(0) (or shorter: inverted()): set the tokenizer to “tokens”, i.e. split strings along spaces,
- inverted(N): with N between 2 and 8 sets the tokenizer to “ngrams(N)”
可以看到,inverted虽然使用了倒排索引,但分词逻辑无非就 tokenbf_v1 和 ngrambf_v1这两种,那么在 like 查询时,使用 tokenbf_v1 分词依然会遇到无法命中索引的情况。
另外值得注意的是,inverted索引截止目前(2023年12月)为止依旧是实验性质,不建议直接应用到生产环境中。
