VictoriaLogs 是 VictoriaMetrics 团队继 VictoriaMetrics时序存储数据库后新推出的开源且用户友好的日志数据库,本篇将详细介绍 VictoriaLogs 的使用和原理
简介
VictoriaLogs 是 VictoriaMetrics 团队新推出的开源且用户友好的日志数据库,主要有以下特性:
- VictoriaLogs 支持常见的日志采集器,如 logstash、filebeat、fluentbit等等
- VictoriaLogs 与 Elasticsearch 和 Grafana Loki 相比在部署和运维上更加简单
- VictoriaLogs 提供强大的查询语言 LogsQL 和 全文搜索能力
- VictoriaLogs 数据压缩率高,相同硬件设备上能够比 Elasticsearch 和 Grafana Loki 存储多30倍以上的数据
- VictoriaLogs 支持多租户
架构
VictoriaLogs 目前只支持单机版。在架构上,与 VictoriaMetrics 十分相似。其中,vlselect 对标 vmselect,负责日志查询,vlinsert 对标 vminsert,负责日志写入,而 vlstorage 则 对标 vmstorage,负责日志数据的存储。
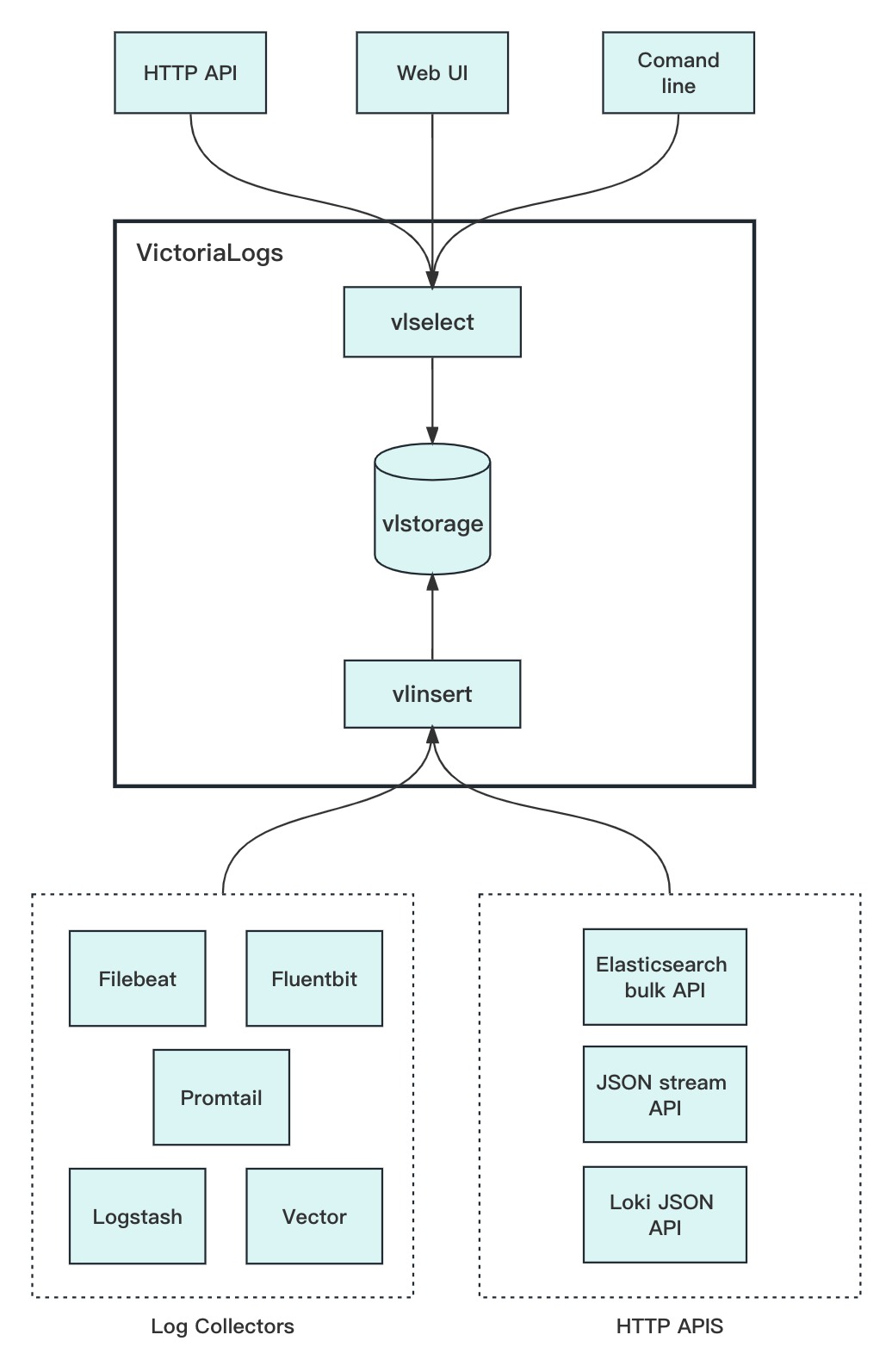
查询
VictoriaLogs 提供了日志查询语言 LogsQL 来实现对日志的检索,可以通过以下几种方式来使用 LogsQL:
- Web UI:VictoriaLogs内置的查询Web页面
- HTTP API:可以通过VictoriaLogs的HTTP API拉取数据
- HTTP API + Command-line:查询HTTP API时,可以结合Shell命令行实现排序、查询数量限制、去重等功能
LogsQL支持以下查询功能:
| 功能 | 示例 | 说明 |
|---|---|---|
| 时间过滤 | _time:5m |
返回最近5min的日志行,也可以过滤时间范围例如_time:[2023-02-01, 2023-03-01) |
| 短语/单词过滤 | "ssh: login fail" |
匹配含有"ssh: login fail"短语的日志行 |
| 前缀匹配 | err* |
匹配含有前缀err的日志行 |
| 正则匹配 | re("err\|warn") |
正则匹配符合"err\|warn"规则的日志行 |
| 范围查询 | request.duration:range[1, 10) |
匹配request.duration字段值为1到10且不等于10的日志行 |
| 精确查询 | exact("error: msg") |
匹配只有error: msg短语的日志行 |
| stream过滤 | _stream:{app="nginx"} |
匹配含有stream字段app且值等于nginx的日志行,stream的概念可以见下面介绍 |
| 空值过滤 | host.hostname:"" |
匹配不含有 host.hostname字段的日志行 |
| 精确前缀匹配 | exact("Processing request"*) |
匹配以Processing request前缀作为最开始的日志行 |
| 顺序匹配 | seq("error", "open file") |
匹配 error 字符串在open file字符串前面的日志行 |
| IPv4范围查询 | user.ip:ipv4_range(127.0.0.0, 127.255.255.255) |
匹配user.ip字段为 127.0.0.0 和 127.255.255.255 之间的日志行,支持单个匹配:user.ip:ipv4_range("1.2.3.4")和CIDR匹配:user.ip:ipv4_range("127.0.0.0/8") |
| 字符范围查询 | string_range(A, C) |
匹配字符串中由A到B字符组成的日志行 |
| 长度范围查询 | len_range(5, 10) |
匹配长度在5和10之间的日志行 |
| 大小写不敏感匹配 | i(error) |
匹配含有error字符串且字符大小写任意的日志行 |
| 逻辑过滤(AND/OR/NOT) | q1 AND q2/q1 OR q2/NOT q |
使用 AND、OR、NOT 组合查询和过滤条件 |
写入
VictoriaLogs 支持目前常见的开源日志 Agent 写入:
同时,VictoriaLogs 也提供了以下 API 来直接写入:
数据模型
VictoriaLogs 支持结构化和非结构化数据,写入的日志至少包含 message 字段,也可以加上任意其他 key=value 字段。一条日志可以通过JSON格式表示如下:
{
"job": "my-app",
"instance": "host123:4567",
"level": "error",
"client_ip": "1.2.3.4",
"trace_id": "1234-56789-abcdef",
"_msg": "failed to serve the client request"
}
VictoriaLogs 会自动将嵌套 JSON 打平成一层,并且数组、数值、和bool类型的数据会被转换成字符串类型,如下:
{
"host": {
"name": "foobar",
"os": {
"version": "1.2.3"
}
},
"tags": ["foo", "bar"],
"offset": 12345,
"is_error": false
}
写入 VictoriaLogs 会转换成:
{
"host.name": "foobar",
"host.os.version": "1.2.3",
"tags": "[\"foo\", \"bar\"]",
"offset": "12345",
"is_error": "false"
}
元字段
VictoriaLogs 支持以下元字段:
_msg:即 message 字段,指具体的日志信息 _time:即时间字段,指日志行的时间,一般在写入时指定 _stream:可以认为是分组标签,将日志根据stream字段划分成不同的组,查询时可指定stream来加快查询速度
1. _msg
_msg 是日志写入时,日志信息实际所在字段,同时也是VictoriaLogs中最小的单元,一个最简单的日志行如下:
{
"_msg": "some log message"
}
2. _time
_time 代表日志行产生的时间,可以在写入时指定日志上的字段作为时间字段的来源,若没有指定则默认以写入时间作为日志行的时间。示例如下:
{
"_msg": "some log message",
"_time": "2023-04-12T06:38:11.095Z"
}
3. _stream
log stream原本是 Grafana Loki 中的概念,VictoriaLogs 也参考并设计了 _stream 字段,根据官方文档说明,_stream 字段最好选取那些比较稀疏且共有的字段。不同 stream 的日志会被分开存储和查询。stream 主要有以下好处:
- 具有相同log stream的数据存放在一起时通常压缩率会比较高,从而降低磁盘空间的使用
- 可以通过 stream 减少查询范围,从而提升查询性能
stream的选取策略:
- 不要选取那些高基数的字段,例如所有日志行或大部分日志行都具有相同的
key-value字段就不适合作为stream,那样没有意义 - stream可以选取那些具有唯一标识的字段,例如 instance、host、container等等
- stream可以选取多个字段
4. 其他字段
除了以上 VictoriaLogs 内置的几个字段,在日志写入时还可以定义任意其他数量的字段,这些字段的作用可以加快日志查询,例如单独使用trace_id:XXXX-YYYY-ZZZZ 字段来查询会比直接使用 _msg:"trace_id=XXXX-YYYY-ZZZZ" 来查询快的多
索引
在VictoriaLogs中,索引是围绕 StreamID 来组织的,因此在介绍索引之前,先简单讲下 StreamID。从上面的介绍可以了解到通过 _stream 字段可以将日志进行分组,而 VictoriaLogs 内部则会通过 StreamID 来区分这些 log stream,StreamID的组成如下:
type streamID struct {
tenantID TenantID
id u128
}
type TenantID struct {
AccountID uint32
ProjectID uint32
}
type u128 struct {
hi uint64
lo uint64
}
可以看到 StreamID 实际上由 TenantID(租户ID)和一串128位的id组成。其中租户ID为写入时指定,不指定则默认为0;id为 stream 字段中的 key-value 对拼接后通过hash算法生成。如果stream 字段在写入时未指定,则默认为 {},同样可以生成 streamID。
在数据写入 VictoriaLogs 后,会生成以下索引:
- tenantID:name:value -> streamID
字段key-value对 到 streamID 的索引,通过这个索引可以从字段的 key-value 对查询到stream块
-
分词token -> 数据列块
-
列值字典(valuesDict) -> 数据列块
-
列最大值和最小值(minValue-maxValue) -> 数据列块
存储结构
1.磁盘目录
VictoriaLogs 以天来规划分区,与 VictoriaMetrics 不同的是,VictoriaLogs 的数据和索引文件是存放在同一个分区目录下的,其中,datadb 目录存放数据文件,indexdb 目录存放索引文件。datadb 和 indexdb 目录下会在持续写入后生成多个 part 目录,后台会根据写入情况合并这些 part 目录以提高检索效率,这其实就是 LSM Tree 的存储过程。
flock.lock
partitions
├── 20230824
│ ├── datadb
│ │ ├── 177E28A617BBB5F2
│ │ │ ├── columns_header.bin
│ │ │ ├── field_bloom.bin
│ │ │ ├── field_values.bin
│ │ │ ├── index.bin
│ │ │ ├── message_bloom.bin
│ │ │ ├── message_values.bin
│ │ │ ├── metadata.json
│ │ │ ├── metaindex.bin
│ │ │ └── timestamps.bin
│ │ ├── 177E28A617BBCABB
│ │ │ ├── columns_header.bin
│ │ │ ├── field_bloom.bin
│ │ │ ├── field_values.bin
│ │ │ ├── index.bin
│ │ │ ├── message_bloom.bin
│ │ │ ├── message_values.bin
│ │ │ ├── metadata.json
│ │ │ ├── metaindex.bin
│ │ │ └── timestamps.bin
│ │ └── parts.json
│ └── indexdb
│ ├── 177E28A617B95BD8
│ │ ├── index.bin
│ │ ├── items.bin
│ │ ├── lens.bin
│ │ ├── metadata.json
│ │ └── metaindex.bin
│ └── parts.json
2. 索引文件
VictoriaLogs 的索引文件与 VictoriaMetrics 的索引文件结构基本一致。
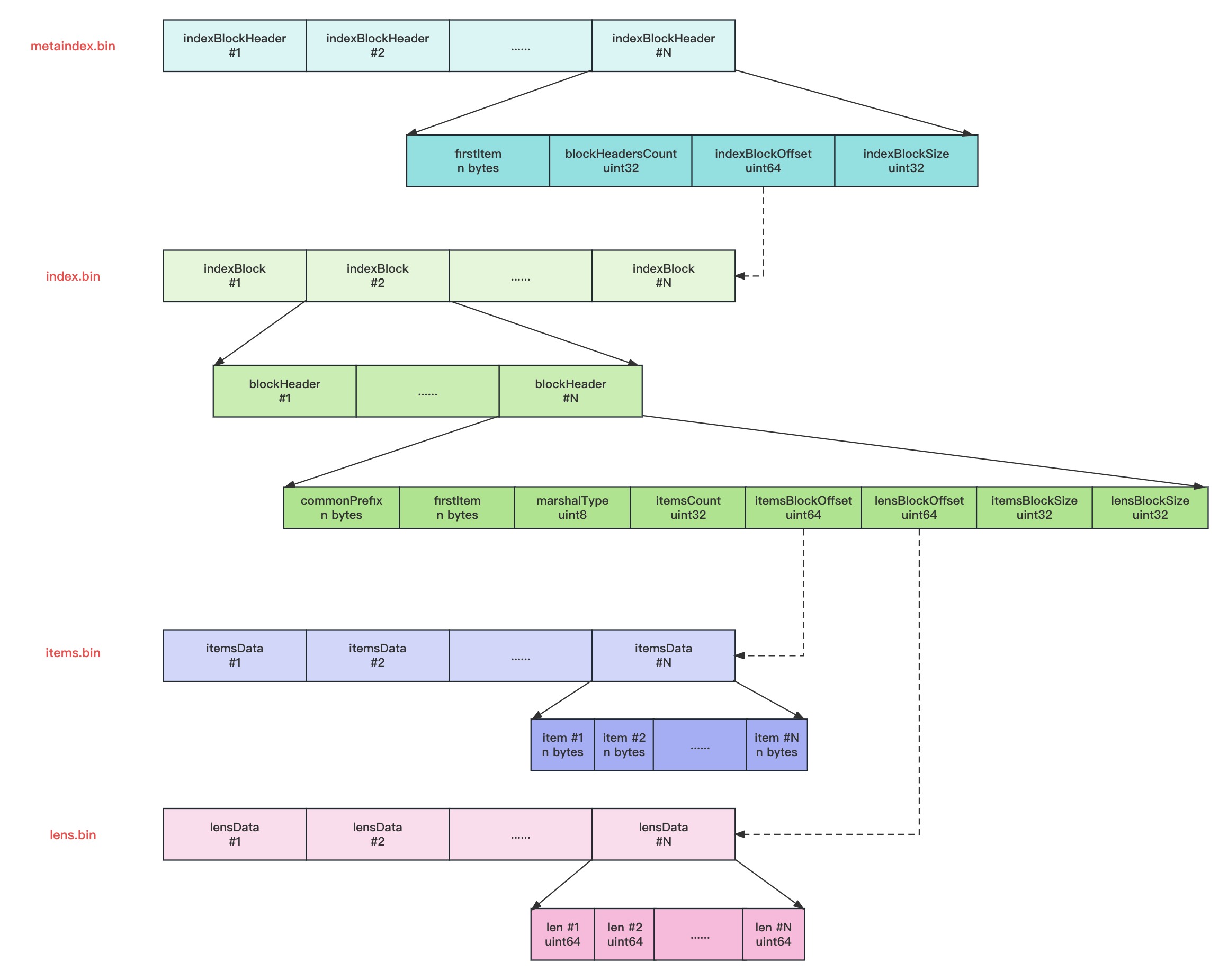
metaindex.bin
metaindex.bin文件中,包含一系列的indexblockheader, 每个indexblockheader中包含最小项firstItem、索引块包含的块头部数blockHeadersCount、索引块偏移indexBlockOffset、索引块大小indexBlockSize。
- indexblockheader在文件中的位置按照firstItem的大小的字典序排序存储,以支持二分检索;
- metaindex.bin文件使用ZSTD进行压缩;
- metaindex.bin文件中的内容在part打开时,会全部读出加载至内存中,以加速查询过滤;
- indexblockheader包含的firstItem为其索引的IndexBlock中所有blockHeader中的字典序最小的firstItem;
- 查找时根据firstItem进行二分检索;
index.bin
index.bin文件中,包含一系列的indexBlock, 每个indexBlock又包含一系列blockHeader,每个blockHeader的包含item的公共前缀commonPrefix、最小项firstItem、itemsData的序列化类型marshalType、itemsData包含的item数、item块的偏移itemsBlockOffset等内容。
- 每个indexBlock使用ZSTD压缩算法进行压缩;
- 在indexBlock中查找时,根据firstItem进行二分检索blockHeader;
items.bin
items.bin文件中,包含一系列的itemsData, 每个itemsData又包含一系列的item。
- itemsData会根据情况是否使用ZTSD压缩,当item个数小于2时,或者itemsData的长度小于64字节时,不压缩;当itemsData使用ZSTD压缩后的大小,大于原始itemsData的0.9倍时,则不压缩,否则使用ZSTD算法进行压缩。
- 每个item在存储时,去掉了blockHeader中的公共前缀commonPrefix以提高压缩率。
lens.bin
lens.bin文件中,包含一系列的lensData, 每个lensData又包含一系列8字节的长度len, 长度len标识items.bin文件中对应item的长度。在读取或者需要解析itemsData中的item时,先要读取对应的lensData中对应的长度len。 当itemsData进行压缩时,lensData会先使用异或算法进行压缩,然后再使用ZSTD算法进一步压缩。
3. 数据文件
VictoriaLogs 的数据文件与 VictoriaMetrics 的数据文件则稍有不同,VictoriaLogs 增加了列结构和bloom过滤索引数据的存储。
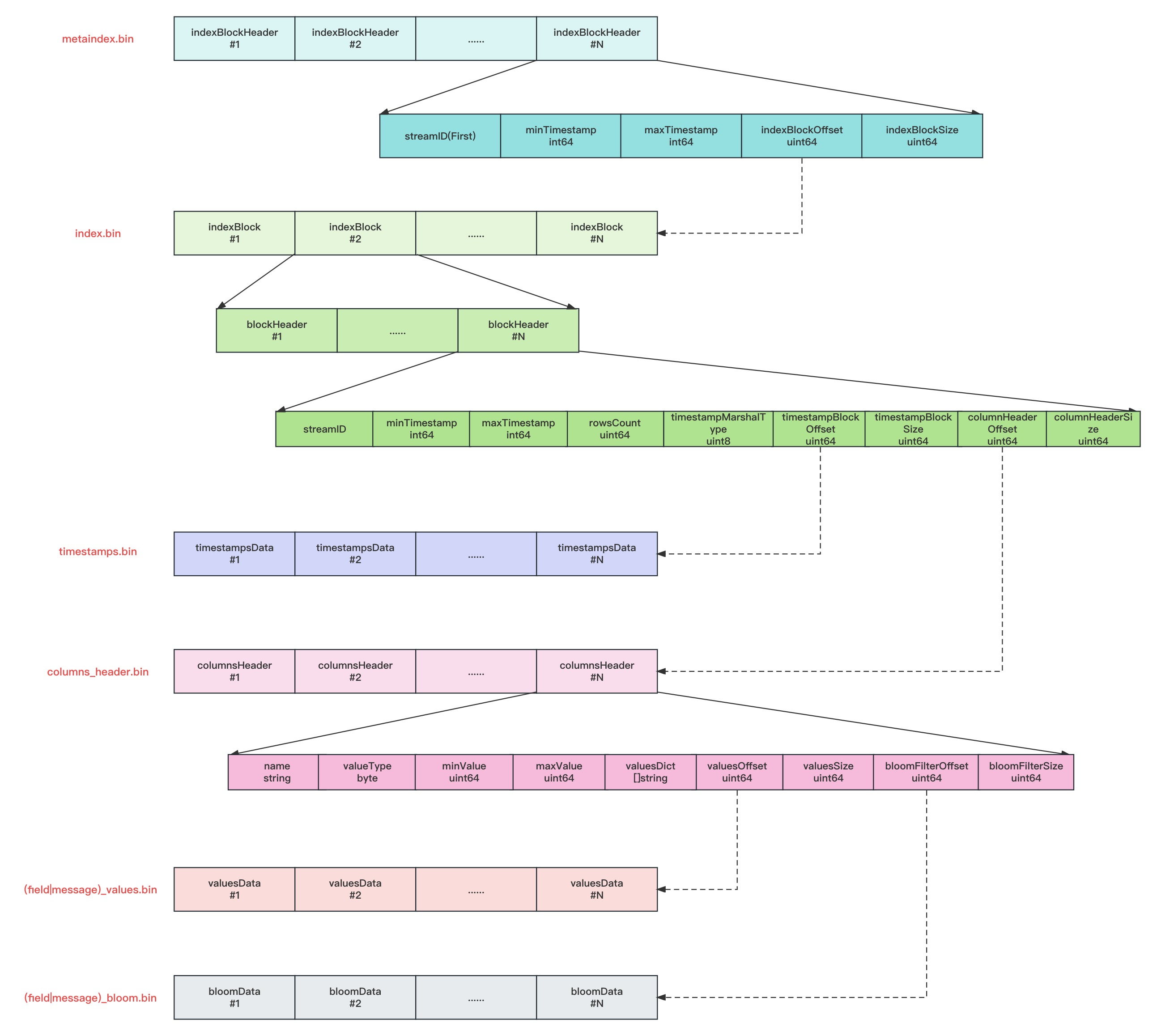
metaindex.bin
metaindex.bin文件中,包含一系列的indexblockheader, 每个indexblockheader中包含StreamID、最小时间戳minTimestamp、最大时间戳maxTimestamp、索引块偏移indexBlockOffset、索引块大小indexBlockSize。
- indexblockheader在文件中的位置按照StreamID的大小排序存储;
- metaindex.bin文件使用ZSTD进行压缩;
- metaindex.bin文件中的内容在part打开时,会全部读出加载至内存中,以加速查询过滤;
- indexblockheader包含StreamID为其索引的IndexBlock中所有blockHeader中的最小StreamID;
- indexblockheader包含最小时间戳minTimestamp为其索引的IndexBlock中所有blockHeader中的最小时间戳minTimestamp;
- indexblockheader包含最大时间戳maxTimestamp为其索引的IndexBlock中所有blockHeader中的最大时间戳maxTimestamp;
- 查找时根据StreamID进行二分检索;
index.bin
index.bin文件中,包含一系列的indexBlock, 每个indexBlock又包含一系列blockHeader,每个blockHeader的包含StreamID、最小时间戳minTimestamp、最大时间戳maxTimestamp、日志行数rowsCount、时间戳数据块偏移timestampsBlockOffset、时间戳数据块大小timestampsBlocSize、columnHeader块偏移tcolumnHeaderOffset、columnHeader块大小columnHeaderSize等内容。
- 每个indexBlock使用ZSTD压缩算法进行压缩;
- 查找时根据StreamID进行二分检索indexBlock中的blockHeader;
timestamps.bin
timestamps.bin文件中,包含一系列时间线的时间戳压缩块timestampsData; timestampsData会根据时序数据特征进行压缩,整体上的压缩思路是:先做时序压缩,然后在做通用压缩。比如,先做delta-of-delta计算或者异或计算,然后根据情况做zig-zag,最后再根据情况做一次ZSTD压缩
columns_header.bin
columns_header.bin文件中,包含了一系列的columnsHeader,每个columnsHeader包含了列名name、列值类型valueType、列最小值minValue、列最大值maxValue、列值字典valuesDict(只有列值类型为Dict的时候才支持)、values块的偏移量valuesOffset、values块大小valuesSize、bloom过滤块的偏移量bloomFilterOffset、bloom过滤块的大小bloomFilterSize
- 查找时若查询语法支持bloom过滤,则可以先使用bloom过滤器进行快速筛选,否则需要遍历整列值进行精确匹配
message_values.bin,field_values.bin
message_values.bin和field_values.bin文件分别包含一系列的日志消息和字段值的压缩块。
values文件中存储的数据类型由columnsHeader中的列值类型valueType决定,主要有以下几种类型:
type valueType byte
const (
// valueTypeUnknown is used for determining whether the value type is unknown.
valueTypeUnknown = valueType(0)
// default encoding for column blocks. Strings are stored as is.
valueTypeString = valueType(1)
// column blocks with small number of unique values are encoded as dict.
valueTypeDict = valueType(2)
// uint values up to 2^8-1 are encoded into valueTypeUint8.
// Every value occupies a single byte.
valueTypeUint8 = valueType(3)
// uint values up to 2^16-1 are encoded into valueTypeUint16.
// Every value occupies 2 bytes.
valueTypeUint16 = valueType(4)
// uint values up to 2^31-1 are encoded into valueTypeUint32.
// Every value occupies 4 bytes.
valueTypeUint32 = valueType(5)
// uint values up to 2^64-1 are encoded into valueTypeUint64.
// Every value occupies 8 bytes.
valueTypeUint64 = valueType(6)
// floating-point values are encoded into valueTypeFloat64.
valueTypeFloat64 = valueType(7)
// column blocks with ipv4 addresses are encoded as 4-byte strings.
valueTypeIPv4 = valueType(8)
// column blocks with ISO8601 timestamps are encoded into valueTypeTimestampISO8601.
// These timestamps are commonly used by Logstash.
valueTypeTimestampISO8601 = valueType(9)
)
其实日志写入到VictoriaLogs时,字段值都会当成字符串来处理,但在实际写入文件过程中,VictoriaLogs会尝试判断原始的数据类型,然后按照不同的数据类型进行对应编码再转换为字节数组,最后每个values block再进行一次ZSTD压缩,大大提升了压缩率。
这里举个例子:
假设现在有一条日志含有offset这个字段,其值为 123456789,如果按字符串类型存储,一个字符占1个字节,则该值占用大小为9字节,如果按 uint16来存储,则仅需要2字节。
message_bloom.bin,field_bloom.bin
message_bloom.bin和field_bloom.bin文件分别包含一系列的日志消息bloom过滤数据和字段值的bloom过滤数据压缩块。
写入过程
1. 初始化日志结构
解析写入日志,提取日志所有字段对应的值,其中特殊字段的提取规如下:
- _msg_field:日志中的消息内容字段,如无设置则默认以
_msgfield为准,Filebeat 和 Logstash 则以message字段为准 - _time_field: 日志中的时间戳字段,如无设置则使用写入时间,Filebeat 和 Logstash 则以
@timestamp字段为准 - _stream_fields: 日志的分组标识字段列表,如无设置则使用默认的log stream:
{} - ignore_fields:忽略日志中的某些字段
每次写入日志行,VictoriaLogs内部会将数据解析并会追加到 LogRows 结构体,当该结构体的数据大小超过设定阈值时,则会往存储引擎logstorage写入数据。LogRows 结构体如下:
type LogRows struct {
// buf holds all the bytes referred by items in LogRows
buf []byte
// fieldsBuf holds all the fields referred by items in LogRows
fieldsBuf []Field
// streamIDs holds streamIDs for rows added to LogRows
streamIDs []streamID
// streamTagsCanonicals holds streamTagsCanonical entries for rows added to LogRows
streamTagsCanonicals [][]byte
// timestamps holds stimestamps for rows added to LogRows
timestamps []int64
// rows holds fields for rows atted to LogRows.
rows [][]Field
// sf is a helper for sorting fields in every added row
sf sortedFields
// streamFields contains names for stream fields
streamFields map[string]struct{}
// ignoreFields contains names for log fields, which must be skipped during data ingestion
ignoreFields map[string]struct{}
}
2. 写入存储引擎 logstorage
logstorage根据天数来规划分区partition,每个partition包含日志数据目录datadb和索引数据目录indexdb,这两个目录下会在持续写入后生成多个part,同时logstorage也会根据情况做part的合并。
为了提升写入效率,logstorage提供了热分区 hot partition。每次写入时,会判断当前的写入块时间与hot partition(即最后一次写入的part)的时间是否一致,如果一致则直接写入hot partition,否则需要根据写入块的时间从partition列表中找到对应的partition再写入,写入完成后hot partition会指向这次写入的partition。
3. 写入分区 partition
写入partition时,会先写索引数据到indexdb,再写日志数据到datadb:
3.1. 写入 indexdb:
遍历写入日志行的streamID,检查 streamID 是否在 indexdb 的 cache 中,若不存在则进行索引的注册:
- tenantID:streamID -> streamTagsCanonical entry(stream key-value数据块)
streamID 到 stream数据的索引,通过这个索引可以从 streamID 查询到 stream字段具体的 key-value对
- tenantID:name:value -> streamID
stream字段key-value对 到 streamID 的索引,通过这个索引可以通过stream字段的 key-value 对查询到stream块
indexdb 的写入结构可以参考上面的索引文件结构,VictoriaLogs 将索引当成一块完整数据直接写入,在查询时可以通过二分查找算法、前缀匹配等快速查询到这些索引数据。有了这些索引的item后,就可以快速筛选出 StreamID 的范围,然后通过这些 StreamID,从 datadb 里面获取对应的数据块再进一步检索。
3.2. 写入 datadb:
根据写入的 Logrows 结构体初始化内存part,过程如下:
Logrows 先按照streamID排序,streamID相同时则按照timestamp排序,随后按照timestamp的顺序遍历 Logrows:
- 写入block块
- 将日志行按照列进行分割提取并存储到block中,其中,timestamp会单独提取成一列
- 相同streamID会被写入同一个block中,block的大小会控制在2MB,超过阈值则切分成两个block
- 如果一个block中的某一列都含有相同的值,则压缩成常量列,即只需保存一对key-value即可
- 写入timestamp列,采用 zstd 压缩
- 写入其他字段列,生成 columnheader
- 对列值进行编码,按照int、float、ipv4、timestamp顺序尝试进行类型编码,如果不是以上这些类型,则默认编码为string类型
- 对列值进行分词然后根据分词创建布隆过滤器
- block块写入完成后会生成blockheader,将其写入到 indexblock 中
- indexblock 超过128K则持久化,采用 zstd 压缩,并生成indexblockheader
分词和生成bloom过滤器的过程如下:
- 首先遍历所有字段值,将整条字符串按符号切割成若干个token,token的组成主要是字母、数字和下划线,即除了这些字符以外,其他字符都当成分隔符
- 根据1中的token列表长度生成只包含0和1的bit数组,然后将所有bit位设置为0
- 遍历1中的token列表,将token进行hash后,在bit数组相应的位置上设置1
- 查询的时候,将查询的短语先分词,然后将分词后的token进行hash,如果hash后在bit数组对应位置值为1,则说明这个token可能存在该日志行中,接下来再与日志行进行精确匹配。
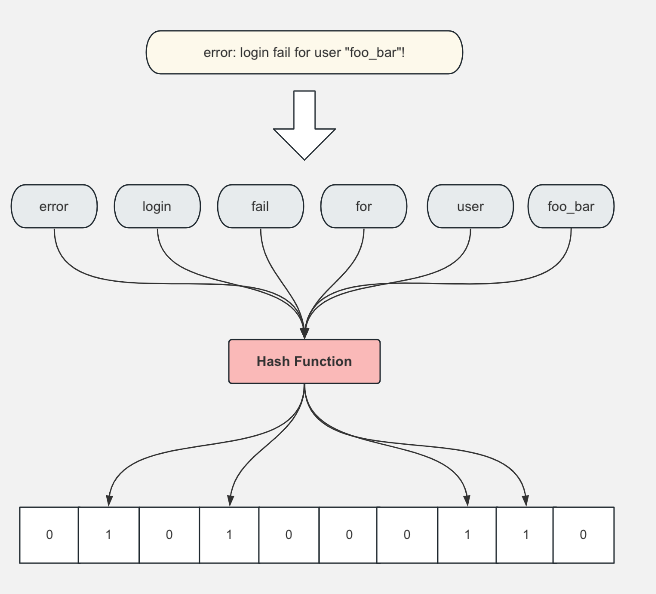
bloom过滤器的作用:用于快速筛选某个单词是否在block中出现过,注意这里有一定概率会出现假阳性,即bloom过滤器计算后显示该单词存在,但实际上block中不存在该单词。
3.3. part合并
内存part需要持久化到硬盘以减少内存消耗,文件part则需要进行合并以提高检索效率,VictoriaLogs按照以下规则进行合并和写入持久化存储:
- logstorage有异步协程会定时1秒遍历得到可以进行合并的内存part
- 内存part是否可以merge的deadline时间由参数
inmemoryDataFlushInterval控制,默认为5秒,即内存part最多只能停留5秒 - 检查内存part是否正在merge,是则将其剔除
- 合并内存part时,判断内存part的大小是否超过了阈值(允许运行内存的10%),是则直接合并写入文件,否则合并后写入内存
- 内存part是否可以merge的deadline时间由参数
- 每次写入时判断内存part数量是否超过阈值15,是则开始异步协程进行所有part的merge,此过程会锁住当前partition写入
- 合并part时,除非全部都是内存part且大小未超过阈值则merge到内存中,否则都merge到文件中
- 内存part数量很多时(超过20个),则阻塞等待直到所有merge成功,避免占用内存过多
- 每次检查part列表中是否有可以合并的part时,都会加一个 partition 级别的锁
从上面的写入过程可以看到,VictoriaLogs的内存使用目前是比较克制的,但同时也降低了写入的吞吐量。另外 VictoriaLogs 和 VictoriaMetrics 一样是没有 WAL 机制的,也就是内存中的数据过多或者停留过久时,丢失数据的风险会相应增大。
查询过程
1. 解析和初始化查询
首先解析查询语句,将查询条件转化成相应的过滤器,并将其中涉及短语的查询进行分词以方便后续进行布隆过滤。
查询条件可以分成两大类:
- stream查询(stream query):即通过 stream 字段进行查询,例如
_stream:{foo=bar} - 字段查询(field query):即通过非 stream 字段进行查询,若不指定字段名则默认为 _msg 字段
其中 stream 查询可以转化成 stream 过滤器(stream filter),由于 stream 过滤器可以缩小数据块(block)的查询范围,因此能够加快查询速度。
对于字段查询,根据实际查询语法可以分成以下查询。其中,有部分查询可以通过分词过滤器加快查询速度,其余查询则无法通过分词过滤器,查询速度和资源消耗相对比较大。
- 可以使用分词过滤器的查询
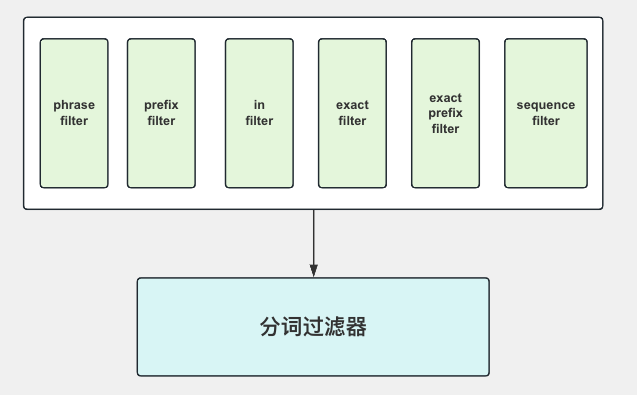
- 无法使用分词过滤器的查询
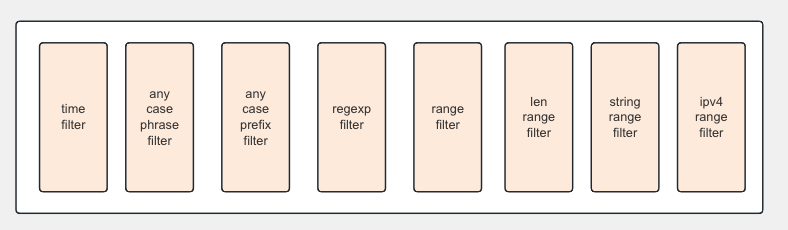
2. 确定查询分区范围
查询条件解析完成后,接下来根据查询的时间范围确定参与查询的分区范围(partition),遍历这些符合条件的分区,针对每个分区进行详细检索。
3. 分区检索
分区由若干个part组成,每个part都有独立的indexdb(存储索引)和datadb(存储数据)。查询时,会遍历所有内存part和文件的part进行检索。
内存part和文件part的结构本质上是一样的,因此检索过程是相同的,只不过内存part是从内存中读取数据,而文件part则是从磁盘中读取数据,内存part相对文件part在查询速度上会比较快。
内存 part 或文件 part 的检索过程可以概括成下图:
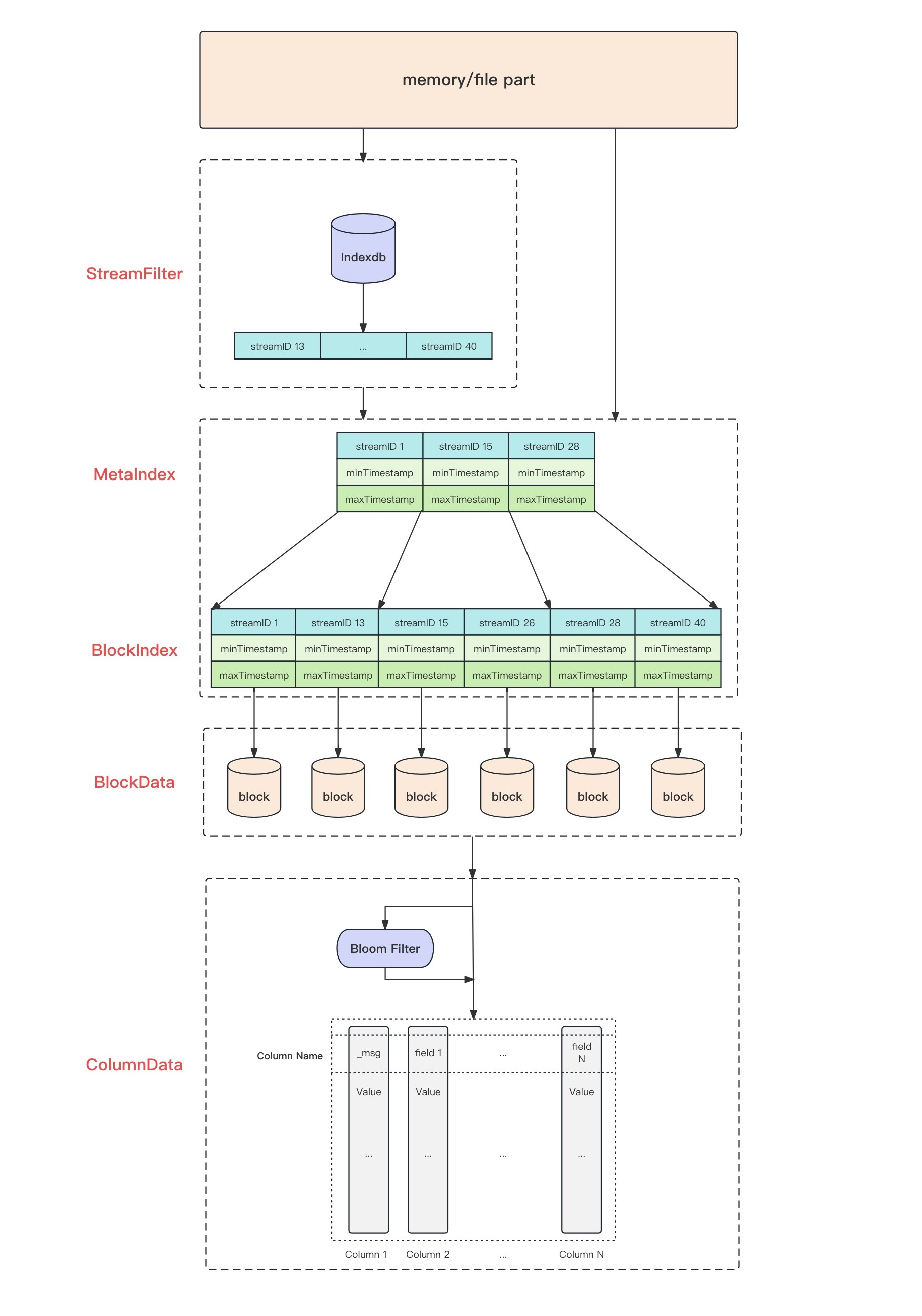
- stream 过滤:indexdb根据stream字段的查询条件,通过二分查找等算法搜索出streamID的索引块,再通过这些索引块确定streamID的列表,若不涉及stream查询,则直接进行下一步查询
- block 范围筛选:通过 streamID索引、时间戳稀疏索引来筛选block
- 若查询中含有stream filter,则通过 streamID 二分查找算法确定 block 范围,若无则遍历该请求租户(默认id为0)下的所有 block
- 若查询中含有时间过滤,则根据时间戳进行 block 的筛选,跳过不符合时间范围的 block
- block 数据筛选:并发查询符合查询条件的每个 block,并发数由cpu核数决定
- 根据 block 元数据初始化整块 block 包含的日志数据
- 按照查询条件的顺序进行筛选过滤,部分查询条件可以通过布隆过滤器(bloom filter)进行初步筛选缩小范围后再进行列值的精确匹配,其余查询则遍历该列的所有值进行匹配
- 返回匹配查询条件的列(目前的VictoriaLogs版本默认不返回不在查询中的字段列)
- 合并block下所有列的查询结果,还原成行数据(JSON格式)并返回
